R: Gráficos
Criando gráficos
Para criar gráficos utilizando a linguagem R, você também dispõe de diversas bibliotecas que oferecem uma ampla gama de opções. Abaixo, apresentamos algumas das principais bibliotecas usadas para visualização de dados em R:
ggplot2: O ggplot2 é uma das bibliotecas mais populares para criação de gráficos em R. Ele é baseado na “gramática dos gráficos” e oferece uma abordagem declarativa para a criação de visualizações. Com o ggplot2, você pode criar facilmente gráficos de dispersão, barras, linhas, boxplots e muito mais, com a capacidade de personalizar cada aspecto do gráfico.
lattice: A biblioteca lattice é conhecida por criar gráficos condicionais em R. Ela é especialmente útil para visualizações de dados multidimensionais, como gráficos de trellis. O lattice fornece uma maneira eficaz de criar painéis de gráficos separados com base em categorias ou variáveis de agrupamento.
base R graphics: R também possui recursos gráficos incorporados que podem ser usados para criar uma variedade de gráficos, como gráficos de dispersão, histogramas, gráficos de barras e muito mais. Embora não tão flexíveis quanto ggplot2 ou lattice, as funções gráficas base R são úteis para visualizações simples e rápidas.
plotly: Similar à biblioteca Python com o mesmo nome, o pacote plotly em R permite criar gráficos interativos e visualizações de dados. Ele suporta uma variedade de tipos de gráficos e oferece recursos interativos, como zoom, pan, dicas de ferramentas (tooltips) e muito mais.
highcharter: O highcharter é um pacote que permite criar gráficos interativos de alta qualidade em R usando a biblioteca Highcharts. Ele é particularmente útil para criar gráficos interativos e dinâmicos, como gráficos de séries temporais interativos.
Cada um desses pacotes tem suas próprias características e vantagens. A escolha do pacote dependerá das suas necessidades específicas e preferências de visualização. Para aprender mais sobre cada uma delas e encontrar recursos úteis, você pode visitar os seguintes sites: ggplot2, lattice, plotly e
highcharter.
Um site interessante para visualizar diferentes tipos de gráficos e seus scripts é o The R Graph Gallery.
Gráficos Univariados
A utilização de gráficos é fundamental na avaliação das variáveis contidas em nossos dados. No contexto dos gráficos, exploraremos em detalhes as funções relacionadas à criação de gráficos no R. No entanto, por enquanto, nos limitaremos a aplicar algumas funções básicas, sem enfatizar muito o aspecto visual dos gráficos. Geralmente, a análise exploratória de dados é uma atividade introspectiva, com o objetivo de compreender as variáveis, em vez de prepará-las para uma audiência externa. Posteriormente, disponibilizaremos um conteúdo com enfoque em aspectos mais visuais utilizando o pacote ggplot2.
Vejamos alguns gráficos básicos de diagnóstico de uma variável numérica, usando como exemplo o “Sepal.Length”, do conjunto de dados “df” (iris):
#Aqui importamos o conjunto de dados iris e fazemos algumas modificações, somente para que possamos práticar a edição desses dados.
data(iris)
df <- iris #Atribuindo os dados iris a um novo objeto chamado df
print(df)
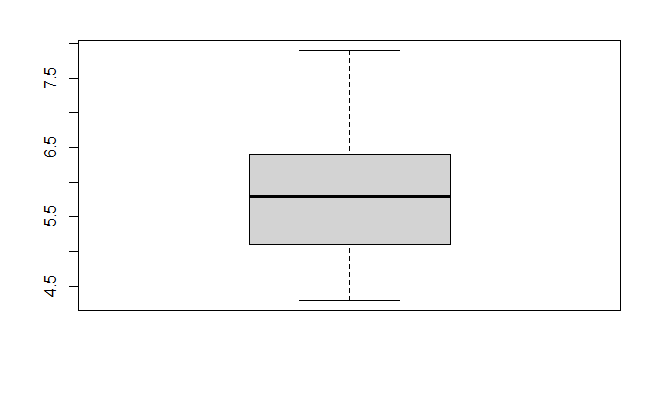
Diagrama de caixas – Boxplot
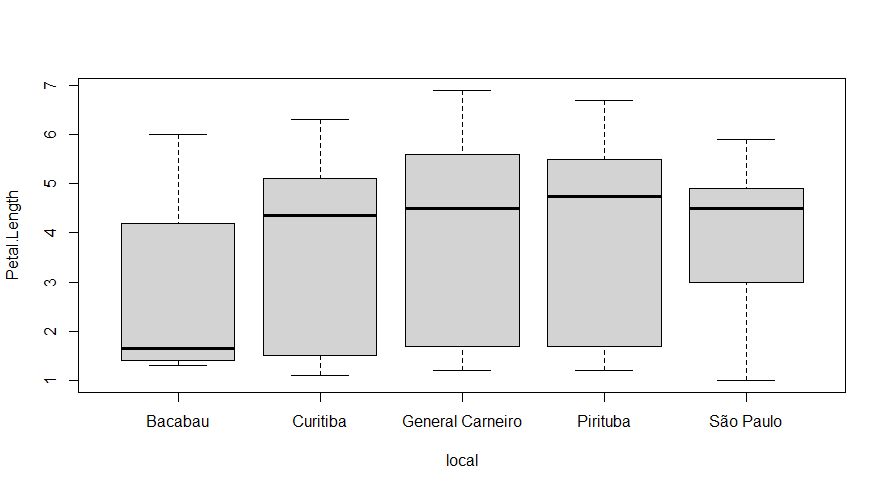
O diagrama de caixas (boxplot) demonstra os quartis que a função quantile retorna. Geralmente usado para explorar a distribuição dos dados e a presença de valores discrepantes (outiliers). A linha inferior da caixa representa o primeiro quartil, o centro da caixa é a mediana (segundo quartil), e a linha superior da caixa corresponde ao terceiro quartil.
boxplot(df$Sepal.Length)
Histograma e Gráfico de Barras
Os histogramas representam a frequência absoluta de variáveis contínuas e os gráficos de barras para variáveis categóricas.
par(mfrow = c(1, 2)) #O parâmetro mfrow permite alterar as porções de visualização da janela gráficas, sendo o primeiro definindo as linhas e o segundo as colunas. Desta maneira, podemos exibir os próximos dois gráficos em uma única janela na aba "plots".
barplot(table(df$Sepal.Length)) #A função table é usada para criar uma tabela de frequência que resume a distribuição de valores em um vetor ou fator. Ela conta quantas vezes cada valor único aparece no vetor e retorna os resultados em uma estrutura de dados tabular. Essa função foi utilizada para gerar o gráfico de barras.
hist(df$Sepal.Length) #Histograma dos dados
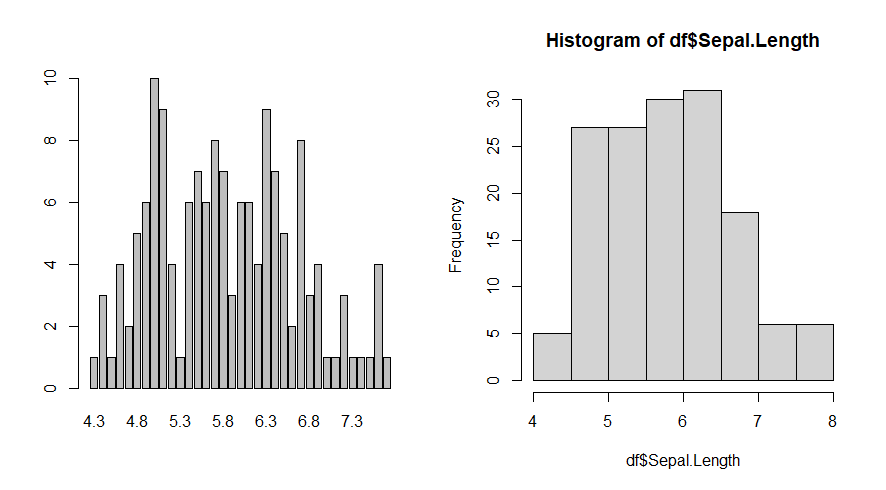
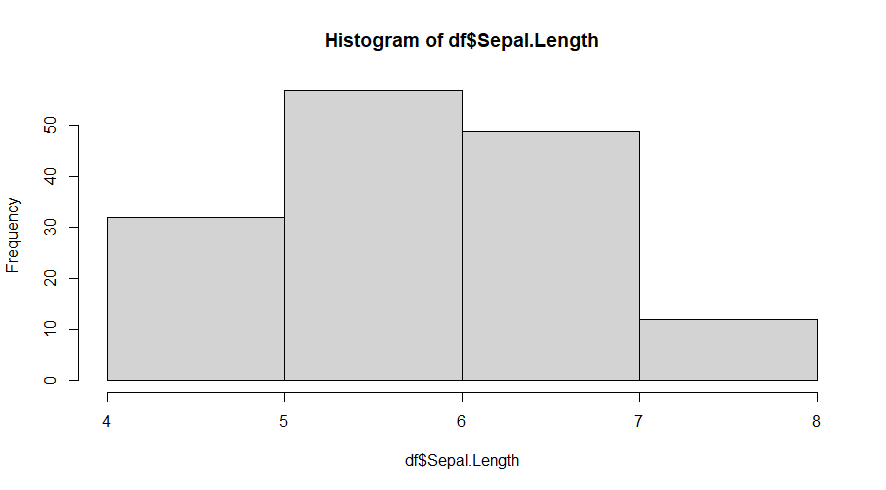
O número de intervalos escolhido tem um impacto significativo na aparência do gráfico histograma, e o R utiliza o algoritmo padrão da função nclass para determinar automaticamente o número de intervalos. Podemos modificar isso utilizando o argumento breaks na função hist:
par(mfrow = c(1, 1)) #Retornar o parâmetro mfrow para o seu padrão isualização de apenas um gráfico na janela plots
hist(df$Sepal.Length, breaks = 4) #Histograma dos dados, definindo intervalos
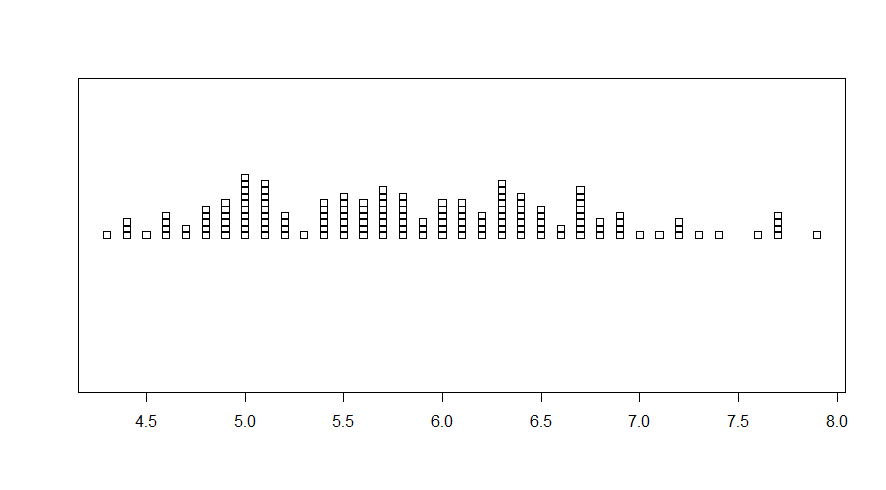
Vamos utilizar a função stripchart() para fazer mais um gráfico dessa variável:
Os gráficos de strip chart são úteis para visualizar a distribuição e a concentração de valores em um conjunto de dados, onde cada ponto corresponde ao valor de uma observação.
stripchart(df$Sepal.Length, method="stack")
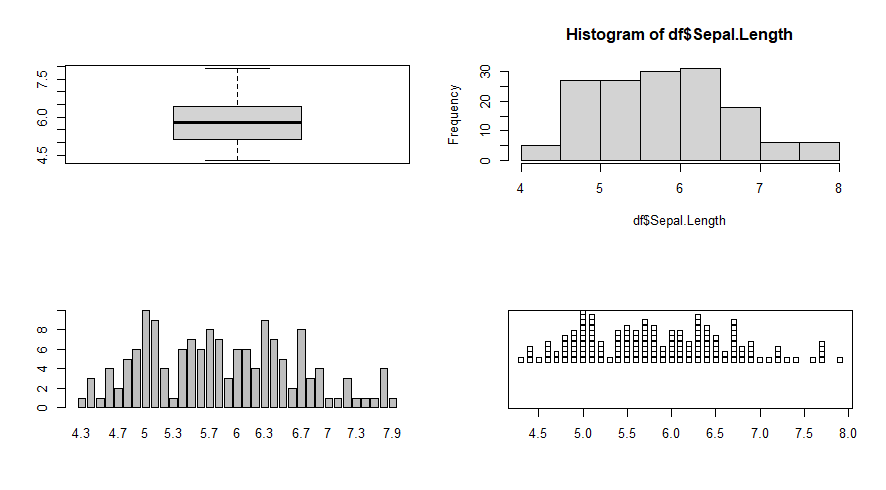
Abaixo incluímos os principais gráficos diagnósticos em uma janela:
par(mfrow = c(2, 2))
boxplot(df$Sepal.Length)
hist(df$Sepal.Length)
barplot(table(df$Sepal.Length))
stripchart(df$Sepal.Length, method = "stack")
par(mfrow = c(1, 1)) #Retornando a janela gráfica ao padrão
Comparações com distribuições teóricas
Avaliando a distribuição dos dados de comprimento da pétala com gráficos exploratórios:
summary(df$Petal.Length)
par(mfrow = c(1, 2))
hist(df$Petal.Length)
boxplot(df$Petal.Length)
par(mfrow = c(1, 1))
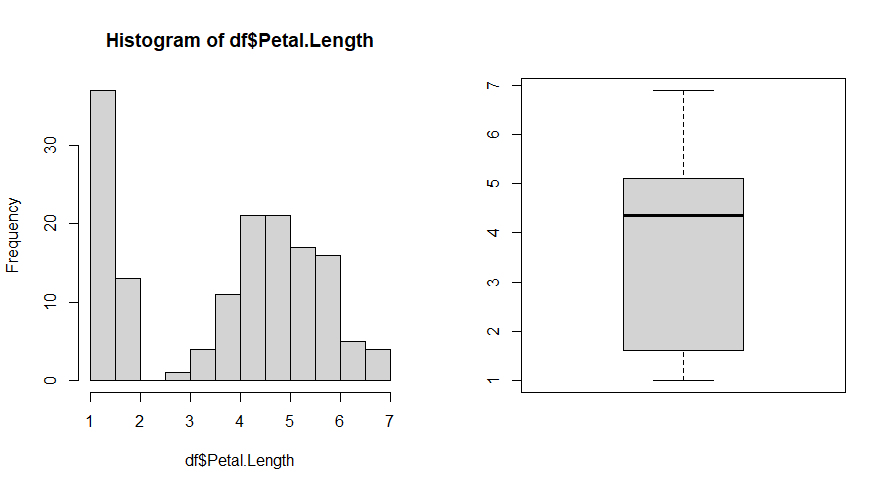
Essa distribuição de valores não parece com uma distribuição normal. Parece muito assimétrica com os dados concentrados nos valores menores. No futuro, disponibilizaremos um conteúdo sobre normalização de dados através do método boxcox, que estará disponível nos conteúdos extras.
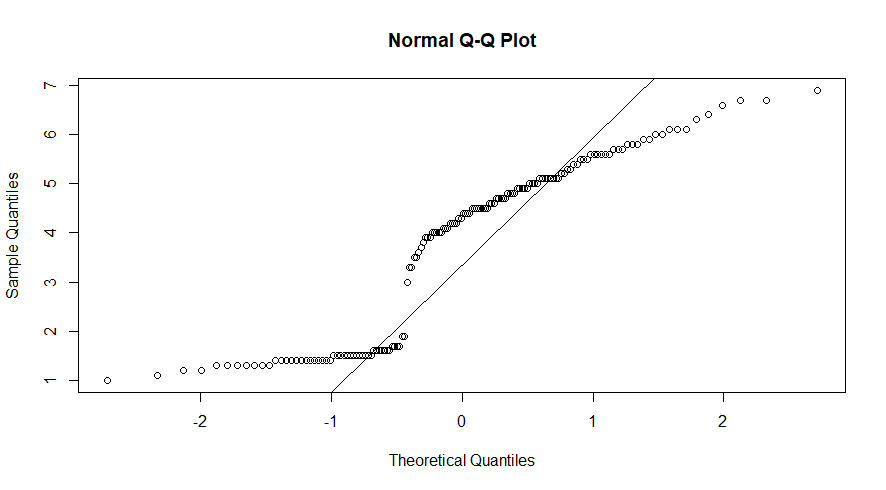
Para avaliar o acoplamento de um variável a uma distribuição normal podemos utilizar os gráficos qqnorm e da relação qqline que compara a distribuição dos valores dos quantis (pontos) da variável com os quantis de uma distribuição normal teórica (linha):
qqnorm(df$Petal.Length) #Plotando os dados
qqline(df$Petal.Length) #Criando a linha que corresponde a normalidade teórica, observe no gráfico abaixo o desvio que os dados apresentam em relação ao que seria se os dados apresentassem normalidade
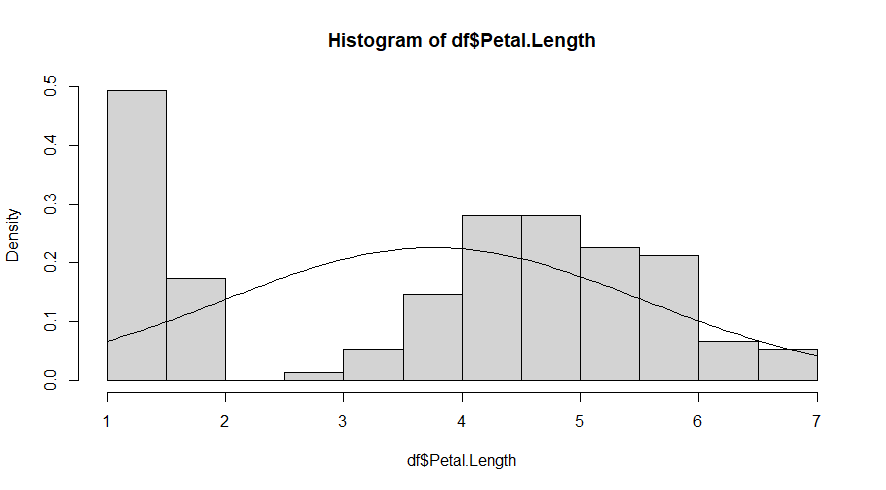
Essa comparação também pode ser feita com um histograma de densidade, com o argumento freq = FALSE e a função curve que produz a curva da distribuição teórica:
hist(df$Petal.Length, freq = FALSE) #Cria o histograma
curve(dnorm(x, mean = mean(df$Petal.Length), sd = sd(df$Petal.Length)), add = TRUE) #Cria a linha da curva de distribuição teórica
Podemos testar esses gráficos com outros conjuntos de dados, como largura da sépala:
par(mfrow = c(1, 3))
hist(df$Sepal.Width)
qqnorm(df$Sepal.Width)
qqline(df$Sepal.Width)
hist(df$Sepal.Width, freq = FALSE)
curve(dnorm(x, mean = mean(df$Sepal.Width), sd = sd(df$Sepal.Width)), add = TRUE)
par(mfrow = c(1, 1))
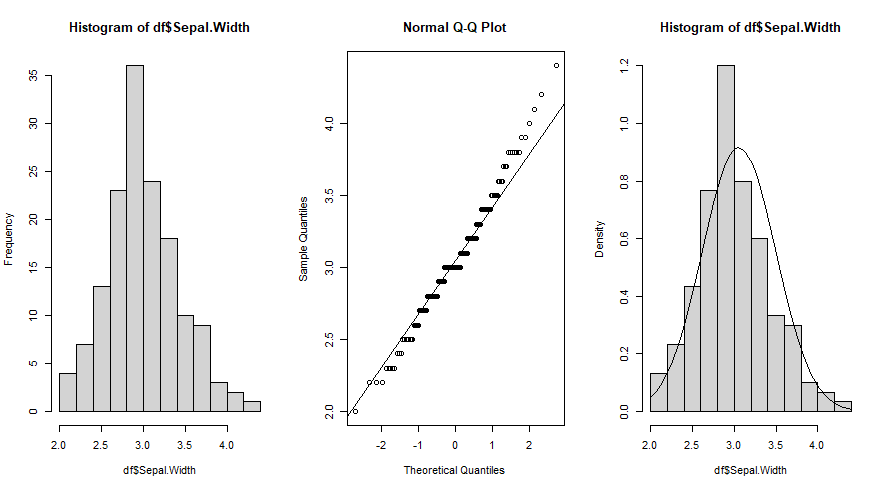
Com os dados Sepal.Width, largura da pétala, foi possível visualizar que está muito mais próximo da normalidade teórica.
Gráficos Bivariados
A relação entre duas ou mais variáveis categóricas pode ser explorada com tabelas cruzadas, por exemplo:
local <- rep(c('General Carneiro', 'Curitiba', 'São Paulo', 'Pirituba', 'Bacabau'), each = 30) #Criando um objeto com diferentes locais, isto é fictício e será utilzado para criar diferentes gráficos
set.seed(150) #Utilizando esta função, podemos preservar sempre os mesmos valores aleatórios
local <- sample(local, 150)#Criando uma ordem aleatória para o objeto local
df$local <- local #Atribuindo nosso objeto a uma variável no nosso dataframe df
table(df$Species) #Visualizando com a função table
table(df$Species,df$local)
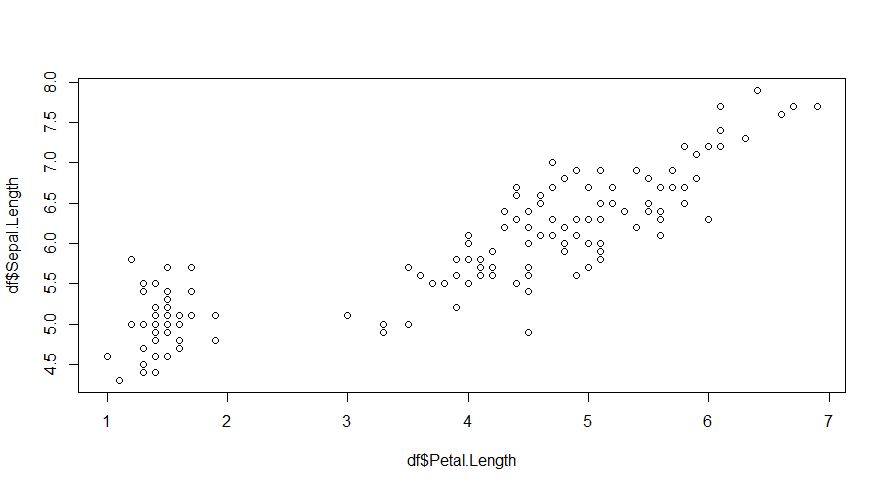
Gráfico de dispersão
O gráfico de dispersão nos permite verificar a relação entre duas variáveis numéricas:
plot(x = df$Petal.Length,y= df$Sepal.Length)
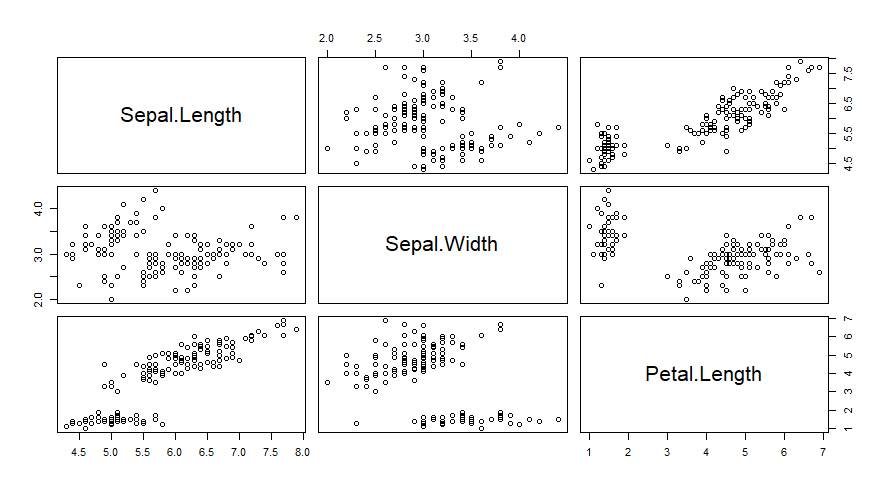
A função pairs cria uma matriz de gráficos de dispersão para visualizar as relações entre várias variáveis
str(df) #Inspecionando os dados
pairs(df[ , c("Sepal.Length", "Sepal.Width" ,"Petal.Length")])
Notações e gráficos com mais de uma variável
Na notação de fórmula estatística do R, o símbolo ~ é utilizado para indicar a relação entre duas variáveis.
fun(y ~ x, data = dados)
fun = função aplicada no objeto dados
y = variável resposta (variável dependente)
x = variável preditora (variável independente)
dados = um data frame contendo os vetores x e y
Esta notação foi criada para os modelos estatísticos, como a regressão linear, mas foi estendida para várias funções gráficas no R onde as relações entre as variáveis podem ser representada. Essa notação facilita a produção de gráficos exploratórios da relação entre variáveis.
plot(Petal.Length ~ Sepal.Length, data = df)
plot(Petal.Length ~ Sepal.Length, data = df, subset = local == "Curitiba") #Subset cria uma seleção somente para o local definido
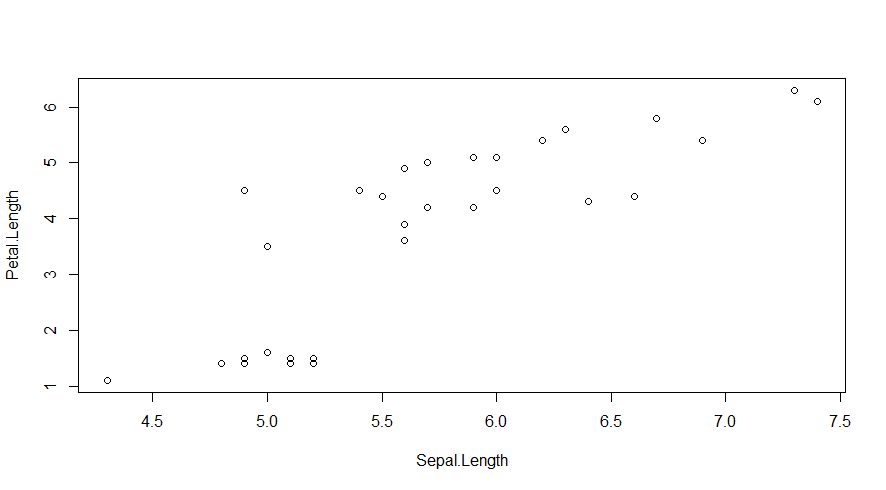
A notação em fórmula nos gráficos tornam o código mais objetivo. Também é possível realizar combinações diferentes, por exemplo entre variáveis contínuas e categóricas:
boxplot(Petal.Length ~ local, data = df)
Pacote Lattice
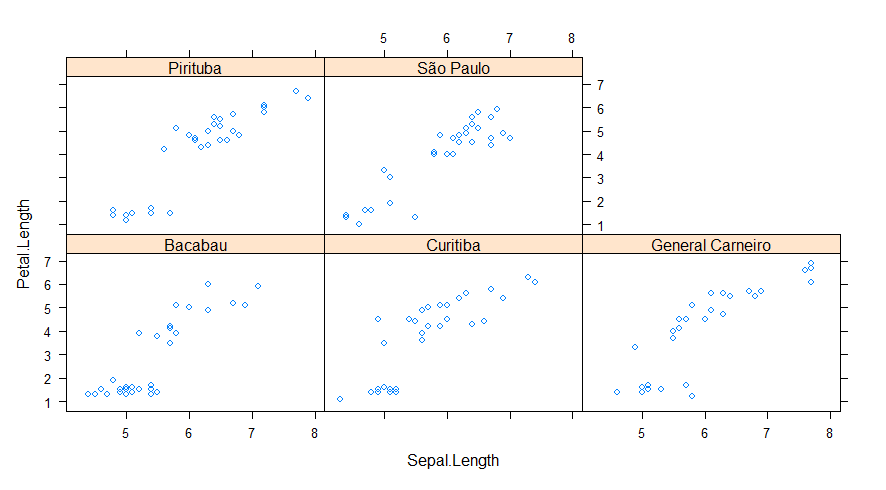
Também podemos incluir um fator condicionante, que aplica a relação proposta dentro de cada nível dos condicionais:
fun(y ~ x | z, data = dados)
z = variável condicionantes
O pacote lattice implementa esta ideia para gráficos:
install.packages('lattice')
library(lattice)
xyplot(Petal.Length ~ Sepal.Length, data = df)
xyplot(Petal.Length ~ Sepal.Length, data = df, subset = local == 'São Paulo')
xyplot(Petal.Length ~ Sepal.Length | local, data = df)
Alterações de parâmetros gráficos
Alguns parâmetros gráficos podem tornar o gráfico mais apresentável. Esses parâmetros gráficos pode ser utilizados como argumentos em diversas funções gráficas onde são pertinentes. Como demonstrado anteriormente, você pode utilizar a função Help para visualizar argumentos de uma função. A partir daí, varias personalizações podem ser realizadas.
‘xlab’ e ‘ylab’ = nomes dos eixos X e Y, respectivamente;
‘main’ = nome do título do histograma
‘col’ = cor da barra (histograma), ou de linhas e símbolos plotados;
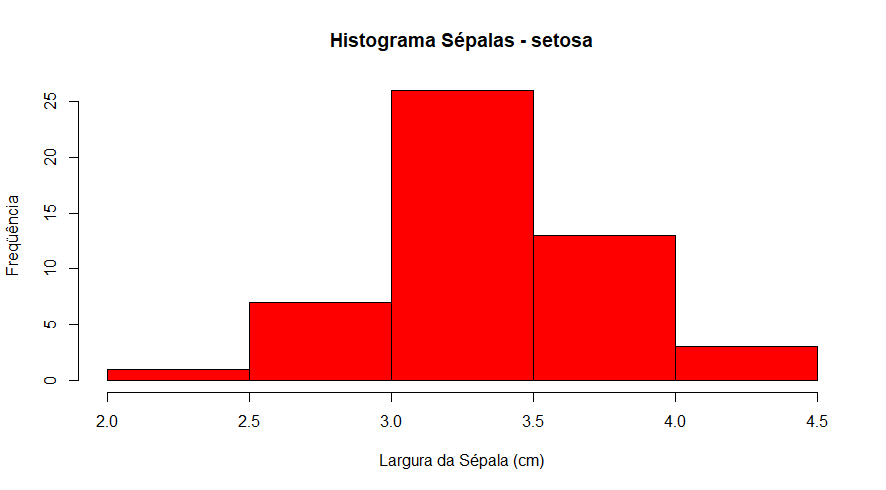
hist( df$Sepal.Width[ df$Species=="setosa" ],
xlab="Largura da Sépala (cm)",
ylab="Freqüência",
main="Histograma Sépalas - setosa",
col = "red" )
Para comparar gráficos, pode ser útil termos mais de uma janela gráfica. A função ‘X11()’ abre uma nova janela gráfica:
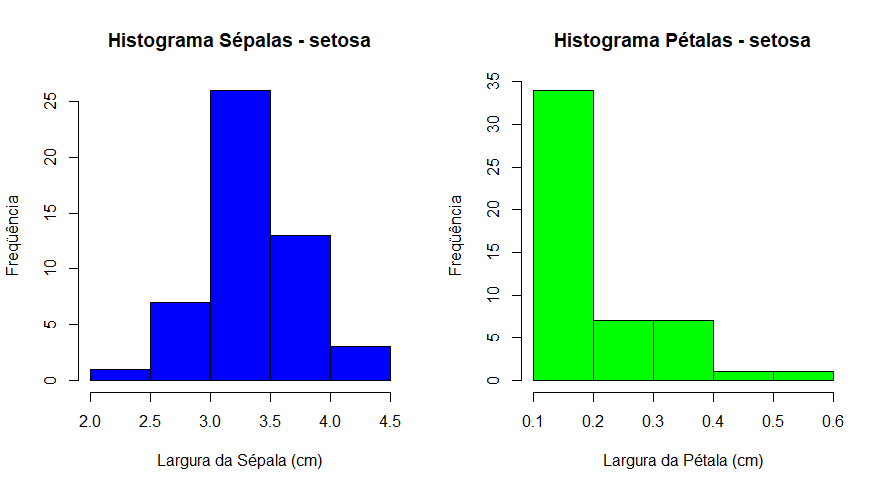
hist( df$Sepal.Width[ df$Species=="setosa" ],
xlab="Largura da Sépala (cm)",
ylab="Freqüência",
main="Histograma Sépalas - setosa",
col = "blue" )
X11() #
hist( df$Petal.Width[ df$Species=="setosa" ],
xlab="Largura da Pétala (cm)",
ylab="Freqüência",
main="Histograma Pétalas - setosa",
col = "green" )
dev.off()
#A função 'dev.off()' fecha uma janela gráfica e faz parte de um conjunto de funções que manipula as janelas gráficas. Nessa manipulação, somente uma janela gráfica pode estar 'ACTIVE' de cada vez, e as janelas são consideradas como estando num círculo, onde podemos passar de uma para outra:
# 'dev.cur()' - diz qual janela gráfica está 'ACTIVE';
#'dev.set(which=dev.cur())' - define qual janela deverá ficar ativa, o argumento 'which' deve ser o número da janela;
#'dev.next(which=dev.cur())' - informa o número da próxima janela gráfica;
#'dev.prev(which=dev.cur())' - informa o número da janela gráfica anterior;
#'graphics.off()' - fecha todas as janelas gráficas.
graphics.off()
Exercícios
A- Crie um gráfico boxplot com a largura da sépala considerando cada espécie diferente para nosso conjunto de dados df.
B -Crie um barplot para largura da sépala considerando cada local diferente, com os dados df. (Dica: Primeiro você pode criar um dataframe com a média da largura da sépala para cada local e depois usar esse output na função barplot. A função aggregate pode ser útil para a criação da média)
C- Carregue o pacote lattice e utilize para criar um gráfico com os dados df.
D- Importe algum conjunto de dados numéricos e crie os principais gráficos diagnósticos com ele.
